
- Introduction
- The Problem: Lost Updates with a Django API Endpoint
2.1 Demo App
2.2 Simulating Concurrent Requests - Understanding Read Committed Isolation Level
3.1 What is Read Committed?
3.2 What it Doesn't Guarantee - Solutions to Avoid Lost Updates
4.1 Solution 1: Atomic Write withF()Expressions
4.2 Solution 2: Change Isolation Level to Serializable
4.3 Solution 3: Useselect_for_update()for Complex Queries - Conclusion
- References and Further Readings
Introduction
Ignoring concepts like proper database transactions and handling race conditions might seem harmless at first, but it’s a recipe for concurrency bugs that are incredibly hard to debug. These bugs have a knack for showing up at the worst possible time—usually once your app has scaled—leading to massive headaches and sleepless nights. In this post, we’ll explore how to prevent these issues in Django, saving your future self from countless hours of frustration.
Relational databases like PostgreSQL offer various levels of transaction isolation to manage concurrent data access. The most common (and often default settings) is Read Committed, which can lead to lost updates in certain scenarios. This tutorial demonstrates the problem and explores solutions using a Django application, but the problem and solutions are relevant for any framework.
We'll:
- Define a basic Django app that increments a counter through an endpoint.
- Explain the Read Committed isolation level and its limitations.
- Provide solutions:
- Using atomic write operations with Django's
Fexpressions. - Switching to Serializable isolation.
- Leveraging
select_for_update()for complex cases.
- Using atomic write operations with Django's
The demo app and code samples can be found in this repository: https://github.com/tartieret/django-isolation-levels
1. The Problem: Lost Updates with a Django API Endpoint
Demo app
Imagine a simple Django app where an endpoint increments a counter stored in a PostgreSQL database. Here's the basic implementation:
# models.py
from django.db import models
class Counter(models.Model):
name = models.CharField(max_length=100, unique=True)
value = models.PositiveIntegerField(default=0)
# views.py
import time
from django.http import JsonResponse
from django.db import transaction
from .models import Counter
@transaction.atomic
def increment_counter(request, name):
"""This endpoint receives a GET request such as:
GET http://localhost:8000/counters/increment/myCounter/
"""
# Retrieve the counter object
counter = Counter.objects.get(name=name)
# Simulate a slow API endpoint
time.sleep(5)
# Increment and save
counter.value += 1
counter.save()
# Return a JSON response
return JsonResponse({"name": name, "value": counter.value})
# urls.py
from django.urls import path
from . import views
urlpatterns = [
path('increment/<str:name>/', views.increment_counter, name='increment_counter'),
]
Here, when the /counters/increment/<name>/ endpoint is called, it retrieves the counter, increments its value, and saves the updated value.Simulating Concurrent Requests
Using the admin portal, let's create a first counter called "test," with initial value of zero:

Simulating Concurrent Requests
We'll now try to send multiple requests to this endpoint in parallel, as an example of what could happen in real life with multiple concurrent users.
To simulate concurrent requests, we can use the concurrent.futures module in Python to send multiple requests in parallel and build the following run_test.py script:
import requests
from concurrent.futures import ThreadPoolExecutor
URL = "http://localhost:8000/counters/increment/test/"
# Function to send a request
def send_request(url):
response = requests.get(url)
print(response.json())
# Send 10 requests in parallel
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [executor.submit(send_request, URL) for _ in range(10)]
print("All requests completed.")
The script above will send ten concurrent requests to our local web server. Intuitively, we would expect the final counter value to be equal to 10. Let's run it!
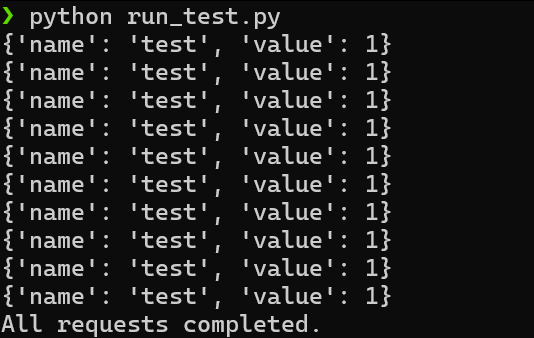
What's happening? Each concurrent request returns a value of 1 for the counter!!!
Checking the counter in the admin portal, we can verify that the final value is indeed 1, in spite of having processed ten requests to increment it.

The schematic below gives a visual representation of what happened:
- The server receives request #1 (in blue), and a zero value is retrieved from the database. It takes a while for the transaction to finish and for the
counter = counter + 1operation to be committed. - In the meantime, request #2 (in red) is received and processed similarly. It starts by reading the counter's current value (zero) in the database and incrementing it by one.
- ...
- Similarly, request #n (in green) is received, reads the value of the counter, and commits a new value of
0 + 1 = 1to the database after about 5 seconds.
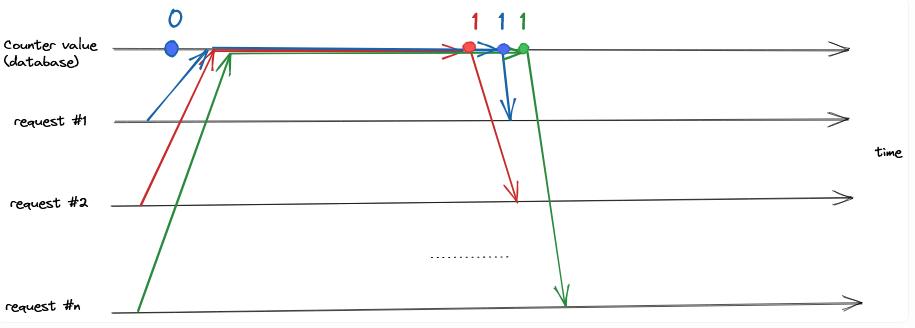
This problem is known as a lost update. Another transaction overwrites changes made by one transaction without the latter being aware of the former's change.
This typically happens when two or more transactions access the same data and then perform an update based on what was read. If there is no locking mechanism in place, we are losing some of the updates as the defaut isolation level (read committed) only guarantees that each transaction is based on a value that was previously committed.
2. Understanding Read Committed Isolation Level
What is Read Committed?
Read Committed is the default isolation level in PostgreSQL, Microsoft SQL server, and other relational databases. It ensures that:
- When reading from the database, we only see data that has been committed (no dirty reads).
- When writing to the database, we only overwrite data that has been committed (no dirty writes)
What it Doesn't Guarantee
Read Committed does not prevent non-repeatable reads or lost updates:
- Non-repeatable reads: The same query can return different results within a transaction.
- Lost updates: Two transactions can overwrite each other's updates because they operate on the same snapshot of the data.
In our example, all transactions read the same value (0), increment it, and overwrite each other's result.
A full description of transaction guarantees and isolation levels is outside the scope of the present article, but I refer you to the following resources for more information:
- PostgreSQL transaction isolation: https://www.postgresql.org/docs/current/transaction-iso.html
- Designing Data-Intensive Applications, by Martin Kleppman (Chapter 7): https://www.oreilly.com/library/view/designing-data-intensive-applications/9781491903063/
3. Solutions to Avoid Lost Updates
Solution 1: Atomic Write with F() Expressions
The trivial example given above can be avoided by using an atomic update operation, which removes the need to read-modify-write. For example, the counter update can be performed using the following SQL query:
UPDATE counters SET value = value + 1 WHERE name='test';
Django's F() Expressions allow you to perform atomic operations at the database level without retrieving and updating the value in Python, which avoids race conditions.
Using this approach, we can add a new endpoint to increment our counter:
# ...
from django.db.models import F
from django.db import transaction
def increment_counter_atomic(request, name):
with transaction.atomic():
# Atomically increment the counter
Counter.objects.filter(name=name).update(value=F('value') + 1)
counter = Counter.objects.get(name=name)
return JsonResponse({"name": name, "value": counter.value})
Testing again with ten concurrent requests, our counter now increases from 1 to 11, which is what we want:
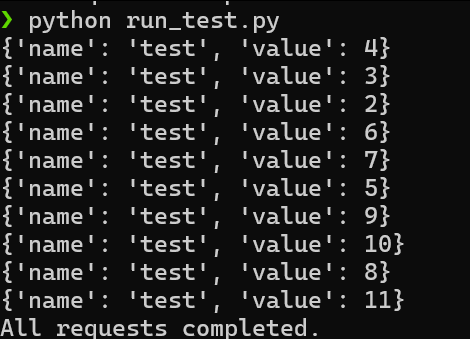
This is a simple and efficient solution, but it is limited to simple operations that can be expressed as an atomic update.
Solution 2: Change Isolation Level to Serializable
A more radical option is to modify the Django settings to use a different isolation level, such as repeatable read or serializable. This can be done for the entire application directly in the Django settings :
from django.db.backends.postgresql.psycopg_any import IsolationLevel
DATABASES = {
# ...
"OPTIONS": {
"isolation_level": IsolationLevel.SERIALIZABLE,
},
}
The Serializable isolation level prevents concurrent transactions from interfering with each other. It ensures that transactions are executed as if they ran sequentially.
However, serializable transactions may fail with serialization errors if concurrent transactions conflict, requiring retries. Stricter locking can also significantly impact performance.
Alternatively, this can be done for specific raw queries by explicitly setting the isolation level, as shown below:
with connection.cursor() as cursor:
cursor.execute("BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;")
cursor.execute("SELECT ... ")
# ...
Solution 3: Use select_for_update() for Complex Queries
Reading and updating an object through multiple steps is a very common use case and is supported by modern relational databases, thanks to the SELECT ... FOR UPDATE statement. With this statement, the rows that are selected are locked, preventing any concurrent update until the current transaction is committed
When we try to use this statement, the rows that we are trying to access may be already locked by another transaction. In that case, we have several options:
- wait until the concurrent transaction finishes
- don't wait and return an error (
NOWAIT) - skip any locked row (
SKIP LOCKED)
Django includes a select_for_update function in its Queryset API , with the following signature:
select_for_update(nowait=False, skip_locked=False, of=(), no_key=False)
Note that rows of selected objects specified in select_for_update are locked in addition to rows of the queryset’s model.
Using this function, we can build a new view that will lock the counter instance to prevent concurrent updates:
import time
from django.db import transaction
from django.http import JsonResponse
from .models import Counter
def increment_counter_lock(request, name):
with transaction.atomic():
# Lock the row to prevent concurrent access
counter = Counter.objects.select_for_update().get(name=name)
time.sleep(5)
counter.value += 1
counter.save()
return JsonResponse({"name": name, "value": counter.value})
Running our test script again, we can see that the counter is properly incremented. However, even if the requests are sent concurrently, they are only executed sequentially due to the lock on the counter table. The screenshot below shows the timestamp when each response is received, with a clear 5-second delay between each response.
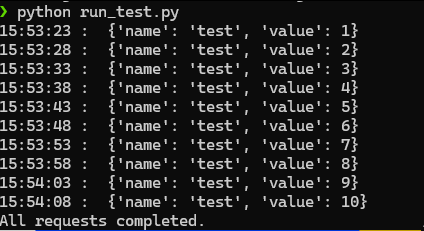
5. Conclusion
Lost updates are a common issue when using the default Read Committed isolation level in relational databases. Ignoring this issue can lead to concurrency bugs that often manifest at higher scales or under heavy load.
In a Django application, you can prevent lost updates using the following techniques:
- Switch to Serializable Isolation for strict guarantees, but with a performance trade-off.
- Use
F()expressions for atomic writes when operations are simple. - Leverage
select_for_update()to lock rows during complex updates.
Choosing the right approach depends on your application's requirements for consistency and performance.
6. References and Further Reading
Below are resources that provide more context and depth to the topics discussed in this document:
-
Django QuerySet API Reference: Detailed documentation on QuerySet methods, including
select_for_updateandF()expressions. -
PostgreSQL: Transaction Isolation: Explanation of the different isolation levels supported by PostgreSQL.
-
MySQL: InnoDB Isolation Levels: Information on MySQL's implementation of isolation levels and their guarantees.
-
"Designing Data-Intensive Applications" by Martin Kleppmann, Chapter 7: An excellent overview of transaction concepts and their implications for developers.
These resources will help you dive deeper into Django, database isolation levels, and concurrency handling techniques.
Posted on December 18, 2024 in django